
I have already blogged about software that allows actors facial expressions to be edited in post. Now take a look at Face2Face: Real-time Face Capture. It can map new facial expressions real time over video. While very interesting from a technological viewpoint, the idea of ‘photoshopping” video will certainly affect journalistic ethics and the trustworthiness of video evidence.
From Michael Zhang Petapixel.
Face swap camera apps are all the rage these days, and Facebook even acquired one this month to get into the game. But the technology is getting more and more creepy: you can now hijack someone else’s face in real-time video.
A team of researchers at the University of Erlangen-Nuremberg, Max Planck Institute for Informatics, and Stanford University are working on a project called Face2Face, which is described as “real-time face capture and reenactment of RGB videos.”

Basically, they’re working on technology that lets you take over the face of anyone in a video clip. By sitting in front of an ordinary webcam, you can, in real-time, manipulate the face of someone in a target video. The result is convincing and photo-realistic.

The face swap is done by tracking the facial expressions of both the subject and the target, doing a super fast “deformation transfer” between the two, warping the mouth to produce an accurate fit, and rerendering the synthesized face and blending it with real-world illumination.
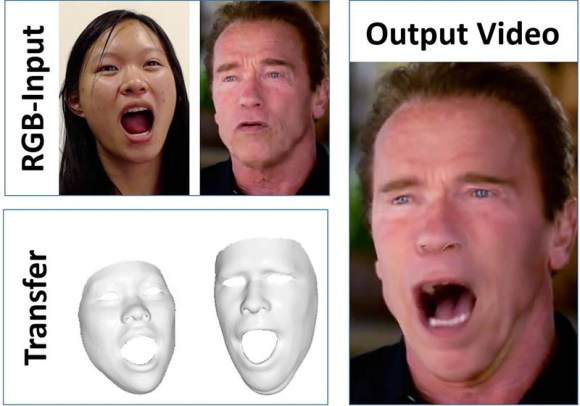
To test the system, the researchers invited subjects to puppeteer the faces of famous people (e.g. George W. Bush, Vladimir Putin, and Arnold Schwarzenegger) in video clips found on YouTube. You can see the results (and an explanation of the technology) in this 6.5-minute video:
Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, June 2016.
Abstract
We present a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. Our goal is to animate the facial expressions of the target video by a source actor and re-render the manipulated output video in a photo-realistic fashion. To this end, we first address the under-constrained problem of facial identity recovery from monocular video by non-rigid model-based bundling. At run time, we track facial expressions of both source and target video using a dense photometric consistency measure. Reenactment is then achieved by fast and efficient deformation transfer between source and target. The mouth interior that best matches the re-targeted expression is retrieved from the target sequence and warped to produce an accurate fit. Finally, we convincingly re-render the synthesized target face on top of the corresponding video stream such that it seamlessly blends with the real-world illumination. We demonstrate our method in a live setup, where Youtube videos are reenacted in real time.
See Matthias Nießner for more info.
It can also be done with 2 live cameras.
ACM Transactions on Graphics 2015 (TOG)
Abstract
We present a method for the real-time transfer of facial expressions from an actor in a source video to an actor in a target video, thus enabling the ad-hoc control of the facial expressions of the target actor. The novelty of our approach lies in the transfer and photo-realistic re-rendering of facial deformations and detail into the target video in a way that the newly-synthesized expressions are virtually indistinguishable from a real video. To achieve this, we accurately capture the facial performances of the source and target subjects in real-time using a commodity RGB-D sensor. For each frame, we jointly fit a parametric model for identity, expression, and skin reflectance to the input color and depth data, and also reconstruct the scene lighting. For expression transfer, we compute the difference between the source and target expressions in parameter space, and modify the target parameters to match the source expressions. A major challenge is the convincing re-rendering of the synthesized target face into the corresponding video stream. This requires a careful consideration of the lighting and shading design, which both must correspond to the real-world environment. We demonstrate our method in a live setup, where we modify a video conference feed such that the facial expressions of a different person (e.g., translator) are matched in real-time.